线性回归(boston房价预测)
(1)数据预处理
1
2
3
4
5
6
7
8
9
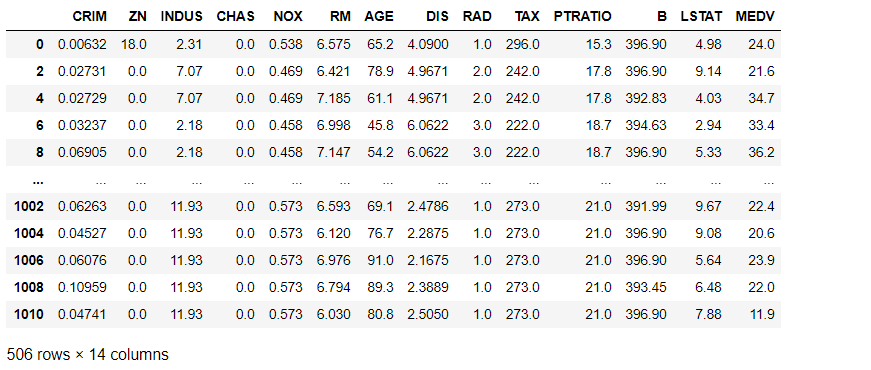
| data = pd.read_csv("data.txt", delim_whitespace=True, names=['CRIM', 'ZN', 'INDUS','CHAS',' NOX','RM','AGE',' DIS',' RAD',' TAX','PTRATIO','B','LSTAT','MEDV'])
for i in range(len(data)):
if((i + 1) % 2 != 1):
data["B"][i - 1] = data["CRIM"][i]
data["LSTAT"][i - 1] = data["ZN"][i]
data["MEDV"][i - 1] = data["INDUS"][i]
data = data.drop([i], axis = 0)
data
|
(2)划分训练集与测试集
由于没有测试数据,我们将数据集划分为训练集与验证集
1
2
3
4
5
6
| data_X = data[['ZN','RM','PTRATIO','LSTAT']]
data_y = data[['MEDV']]
X_train,X_test,y_train,y_test = train_test_split(data_X, data_y, test_size = 0.4)
X_train.shape,X_test.shape,y_train.shape,y_test.shape
|
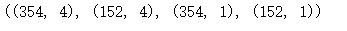
(3)训练数据
划分的训练集训练模型
1
2
| model=LinearRegression()
model.fit(X_train,y_train)
|
(4)计算预测值
划分的验证集使用模型预测
1
2
| y_pred = model.predict(X_test)
y_pred
|
(5)计算平均绝对误差
1
2
| mae = mean_absolute_error(y_pred,y_test)
mae
|
(6)数据分析
1
2
3
4
5
6
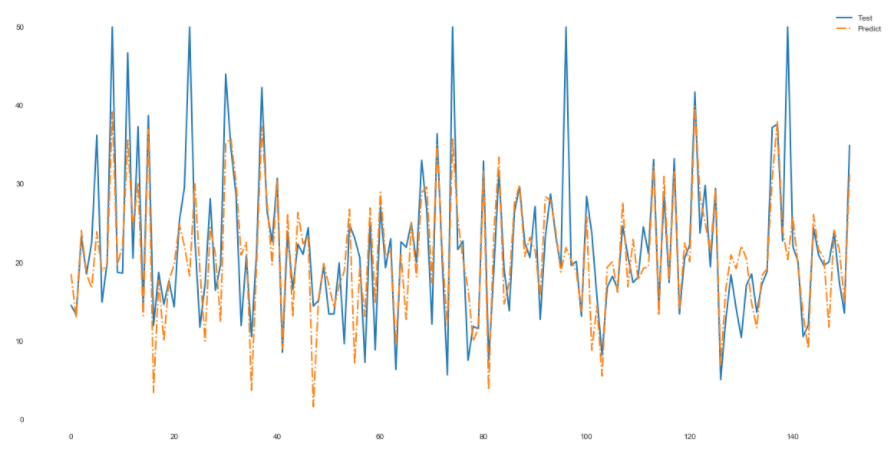
| import matplotlib.pyplot as plt
fig = plt.figure(figsize = (20,10))
plt.rcParams['font.size'] = 15
plt.plot(range(y_test.shape[0]),y_test, linewidth=2, linestyle='-')
plt.plot(range(y_test.shape[0]),y_pred,linewidth=2, linestyle='-.')
plt.legend(['Test','Predict'])
|
逻辑回归(iris分类)
(1)读入数据
1
2
| data = pd.read_csv("G:/大数据/机器学习实验/实验一/iris/iris/iris.data",sep = ',',names = ['Sepal_Length','Sepal_width','Petal_length','Petal_width','Class'])
data
|
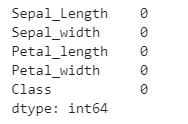
(2) 查看缺失值
运行结果可见无缺失
(3)划分数据集
1
2
3
4
5
|
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
print(X)
|
(4)对数据标准化处理
1
2
3
4
5
6
7
|
stdsc = StandardScaler()
X_train_conti_std = stdsc.fit_transform(X_train[['Sepal_Length','Sepal_width','Petal_length','Petal_width']])
X_test_conti_std = stdsc.fit_transform(X_test[['Sepal_Length','Sepal_width','Petal_length','Petal_width']])
X_train_conti_std = pd.DataFrame(data=X_train_conti_std, columns=['Sepal_Length','Sepal_width','Petal_length','Petal_width'], index=X_train.index)
X_test_conti_std = pd.DataFrame(data=X_test_conti_std, columns=['Sepal_Length','Sepal_width','Petal_length','Petal_width'], index=X_test.index)
|
(5)逻辑回归建立模型
1
2
3
4
5
6
7
8
|
classifier = LogisticRegression(random_state=0)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)
|

(6)正确率
1
| print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(classifier.score(X_test, y_test)))
|

*编码处理
该处理适用一些模型,可用编码将变量数字化,本模型并不需要,以下仅展示使用效果。
1
2
3
4
5
|
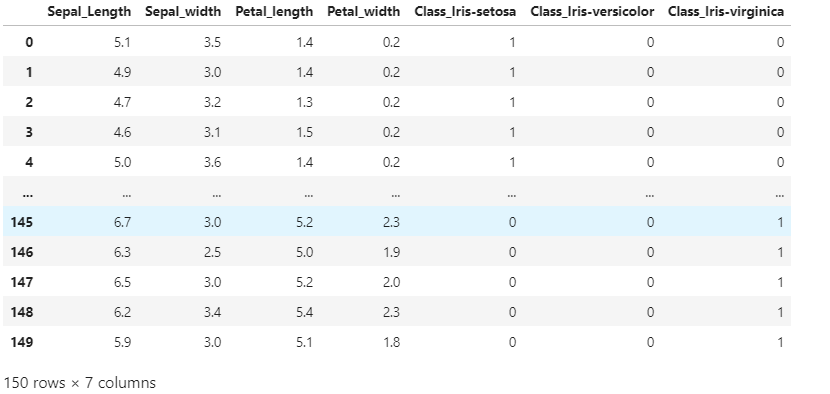
data_dummy = pd.get_dummies(data[['Class']])
data_conti = pd.DataFrame(data, columns=['Sepal_Length','Sepal_width','Petal_length','Petal_width'], index=data.index)
data = data_conti.join(data_dummy)
data
|