一.基础语法
注意:python使用时需要严格缩进,否则在执行是会出现报错
1.注释
2.打印
3. if & else
1
2
3
4
5
6
7
8
| if 判断条件:
print ('true')
else 判断条件:
.......
else 判断条件:
.......
else:
.......
|
4.循环
1
2
3
4
5
6
7
8
9
10
11
| while 判断条件 :
...........
for num in range(a,b):
............
pass
|
5.类型
python中的数据类型不允许改变,可以删除对象,重新分配空间。
字符串
创建
python 的索引可以为负数,反向索引,从右边开始计算
一些常用函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| len(s)
upper()
lower()
swapcase()
capitalize()
title()
ljust(width)
rjust(width)
center(width)
zfill(width)
find()
index()
rfind()
count()
|
不可变性
无法在特定位置修改值,修改会清理旧的对象。
python中的核心类型,数字、字符串以及元祖是不可变的,而字典与列表可完全自由改变。
1
2
| s = 'w' + s[1:]
s[0] = 'a'
|
列表
列表没有固定类型的约束,用中括号表示,组成对象是有序的,组成的各个对象允许不同。
创建
1
2
| list1 = []
list2 = ['QWQ', 'QAQ', 'QVQ', 'QUQ']
|
访问
一些常用函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| append()
cmp(list1, list2)
len(list)
max(list)
min(list)
list(seq)
count(obj)
extend(seq)
index(obj)
insert(index, obj)
pop([index=-1])
remove(obj)
reverse()
sort(cmp=None, key=None, reverse=False)
|
元祖
元祖是序列,但是它具有不可变性,与字符串类似,它提供了一种完整性的约束,编写大型程序更为方便。元祖角色类似于其他语言中的“常数”声明,这种常数概念在Python中是与对象相结合,而不是变量。
创建
1
2
3
| t1 = ()
t2 = (1,)
t3 = ('QWQ', 'QAQ', 'QVQ', 'QUQ')
|
访问
修改
一些常用函数
1
2
3
4
5
6
| cmp(tuple1, tuple2)
append(value)
len(tuple)
max(tuple)
min(tuple)
tuple(seq)
|
字典
字典是另一种可变容器模型,且可存储任意类型对象,用大括号表示,组成对象是无序的,搜索方式是哈希搜索,速度很快。
创建
1
2
3
| d = {key1 : value1, key2 : value2 }
d1 = {'QWQ': '123', 'QAQ': '456', 'QVQ': '321', 'QUQ': '654'}
d2 = {'QWQ': 123, 321: 456}
|
访问
添加
修改
删除
1
2
3
| del d1['QWQ']
d1.clear()
del d1
|
一些常用函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| cmp(dict1, dict2)
len(dict)
str(dict)
type(variable)
clear()
copy()
fromkeys(seq[, val])
get(key, default=None)
has_key(key)
items()
keys()
setdefault(key, default=None)
update(dict2)
values()
pop(key[,default])
popitem()
|
6.函数定义
规则
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
定义
1
2
3
4
| def functionname( parameters ):
"""comments"""
function_suite
return [expression]
|
7.模块
每一个以扩展名py结尾的Python源代码文件都是一个模块,其他文件可以通过导入这个模块来读取这个模块的内容。Python中本来就有很多模块,这里理解为包,需要使用则安装包。
定义模块
首先我们先建立一个新的py文件取名mode
1
2
3
4
5
| print("QWQ")
x = 'QUQ'
def QAQ():
print(x)
|
加载模块
python在第一次导入后就将模块名加载到内存,后续的import语句会判断模块是否已被导入,若已导入将仅对加载在内存中的模块对象增加了一次引用,不会重新执行模块语句。
使用模块
8.文件
读文件
1
2
3
4
5
| file = open('text.txt', 'r')
file.read()
file.close()
|
写文件
1
2
3
|
file.write('hello word!')
file.close()
|
二.大数据常用包
(只用过部分函数,以后使用了更详细的会更新吧…)
1.pandas
pandas使数据预处理、清洗、分析工作变得更快更简单。核心数据结构:Series、DataFrame。
Series
类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| a1 = np.arange(5)
s1 = pd.Series(a1)
print(s1)
a2 = {'1':1,'2':2,'3':3,'a':'hello','b':'python','c':[1,2]}
s2 = pd.Series(a2)
print(s,type(s2))
a3 =
|
修改
1
2
3
4
5
6
7
8
9
| s2['1'] = 'QWQ'
print(s2)
|
删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| del s2['2']
print(s2)
s2 = s2.drop(['b','c'])
print(s2)
|
数据查看
.head()方法是查看前几行的数据,默认是5行
.tail()方法是查看后几行的数据,默认也是5行
1
2
3
4
5
6
7
8
9
| print(s2.head(2),'\n')
print(s2.tail())
|
DataFrame
DataFrame 是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。
创建
1
2
3
4
5
6
7
| data = {"A":['QWQ','QAQ','QVQ'],"B":[100,200,300],"C":[1,2,3]}
f1 = DataFrame(data)
|
常用函数
排序
统计
去重
1
2
3
4
| newdata.drop_duplicates(subset=['A','B','C','D'],keep=False)
|
读写文件
1
2
3
| data = pd.read_csv("data.txt")
pd.to_csv("d:/snp/test.csv")
|
2.matplotlib
可用于可视化。
1
| import matplotlib.pyplot as plt
|
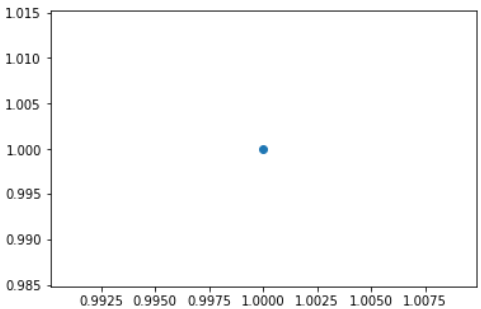
散点图
1
2
3
4
5
| plt.scatter(x, y, marker=None)
plt.scatter(1, 1, marker=None)
|
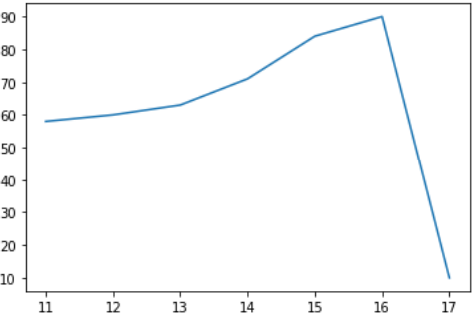
折线图
1
2
3
| x = ['11','12','13','14','15','16','17']
y = [58,60,63,71,84,90,10]
plt.plot(x,y)
|
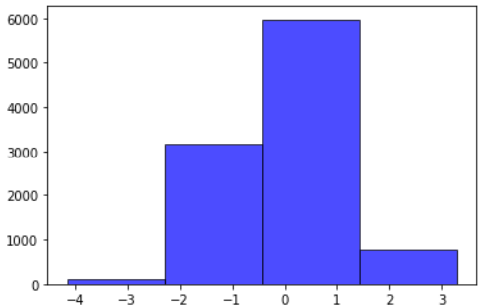
直方图
1
2
3
4
5
| import numpy as np
import matplotlib.pyplot as plt
data = np.random.randn(10000)
plt.hist(data, bins=4, normed=0, facecolor="blue", edgecolor="black", alpha=0.7)
|
条形图
1
2
3
4
5
6
7
| from matplotlib import pyplot as plt
from matplotlib import font_manager
b = [56.01, 26.94, 17.53, 16.49, 15.45, 12.96, 11.8, 11.61, 11.28, 11.12, 10.49, 10.3, 8.75, 7.55, 7.32, 6.99, 6.88,
6.86, 6.58, 6.23]
plt.figure(figsize=(15,7))
plt.bar(range(len(b)),b,width=0.3)
|
箱线图
1
2
3
4
| from matplotlib import pyplot as plt
dataArray=[1,6,2,11,8,8,10,5,4,5,3,7,15]
plt.boxplot(dataArray,labels=["A"])
|
饼图
1
2
3
4
5
6
7
8
| import matplotlib.pyplot as plt
labels = 'A', 'B'
sizes = [15, 30]
colors = ['blue', 'gold']
explode = (0, 0)
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', shadow=False, startangle=90)
|
热力图
1
2
3
4
5
| from matplotlib import pyplot as plt
X = [[1,2],[3,4]]
plt.imshow(X)
plt.colorbar()
|
雷达图
1
2
3
4
5
6
7
8
9
10
11
12
| import matplotlib.pyplot as plt
import numpy as np
theta = np.array([2.55,4.75,3,1.25,1.65])
r = [20,60,40,80,20]
plt.style.use('ggplot')
plt.polar(theta*np.pi,r,"r-",lw=1)
plt.fill(theta*np.pi,r,'r',alpha=0.75)
plt.ylim(0,100)
plt.grid(True)
|
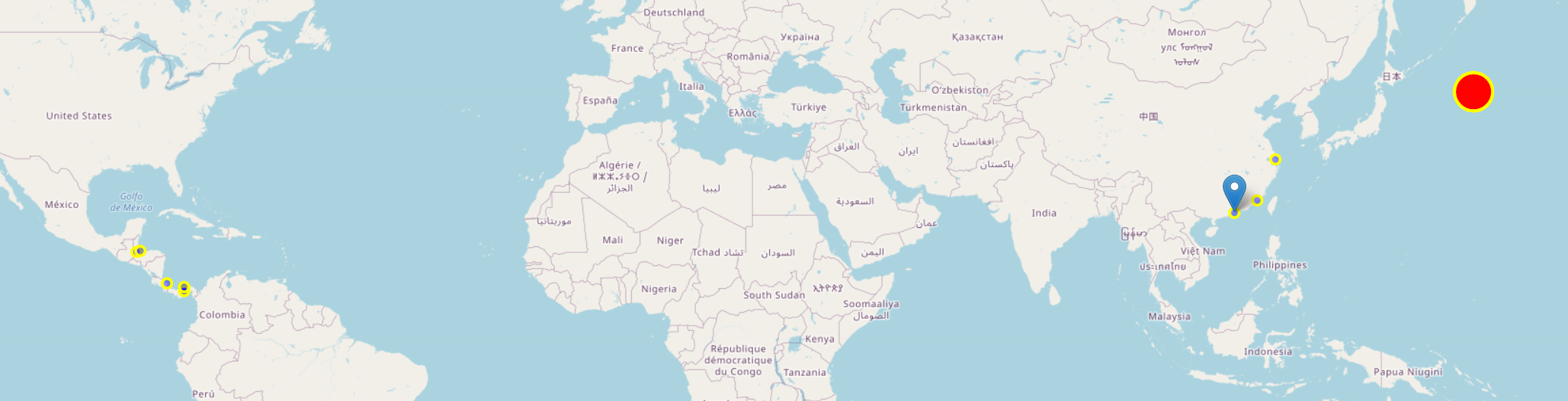
华为云比赛画的航海图部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import pandas as pd
import folium
world_map = folium.Map()
world_map
list = []
lat = 0
lng = 0
incidents = folium.map.FeatureGroup()
df = pd.read_csv("get_test_port.csv",usecols = [0,1,2,3,4,5], encoding = 'gbk')
af = pd.read_csv("loadingOrder.csv",usecols = [0], encoding = 'gbk')
for i in range(len(af)):
s = af.iat[i,0]
incidents = folium.map.FeatureGroup()
world_map = folium.Map()
for j in range(len(df)):
if af.iat[i,0] == df.iat[j,0]:
lat = df.iat[j,2]
lng = df.iat[j,1]
nlat = df.iat[j,4]
nlng = df.iat[j,3]
incidents.add_child(
folium.CircleMarker(
[lat, lng],
radius=20,
color='yellow',
fill=True,
fill_color='red',
fill_opacity=0.4
)
)
incidents.add_child(
folium.CircleMarker(
[nlat, nlng],
radius=5,
color='yellow',
fill=True,
fill_color='blue',
fill_opacity=0.4
)
)
world_map.add_child(incidents)
folium.Marker([nlat, nlng], popup=df.iat[j,5]).add_to(world_map)
s = af.iat[i,0] + ".html"
world_map.save(s.format(af.iat[i,0]))
print(af.iat[i,0] + "已生成")
|
列举其中一张图